Управление большими объемами данных может оказаться непростой задачей для менеджеров данных, особенно если ваш запрос или результаты сканирования занимают несколько страниц. Разбивка на страницы в DynamoDB позволяет базе данных обрабатывать большие объемы данных, разбивая результаты на несколько управляемых страниц. В этой статье объясняется разбиение на страницы DynamoDB и приводятся различные возможные варианты использования и примеры. Также показано, чем нумерация страниц в DynamoDB отличается от нумерации страниц в других базах данных.
Что такое пагинация в DynamoDB?
Как правило, разбиение на страницы, происходящее от слов «страницы», представляет собой метод, который используется базами данных для разделения записей данных на несколько фрагментов, сегментов или страниц. А поскольку AWS DynamoDB поддерживает хранение больших объемов данных, он предлагает надежные возможности разбиения на страницы.
Компонент разбивки на страницы DynamoDB гарантирует, что вы можете получить только до 1 ГБ данных за сканирование или запрос. Хотя это настройка по умолчанию, вы можете добавить параметр limit в запрос, чтобы указать ограничение. Кроме того, вы можете установить ограничение на количество записей в каждом запросе сканирования.
Примечательно, что существует несколько различий между разбиением на страницы в DynamoDB и разбиением на страницы в типичной базе данных SQL. Совершенно очевидно, что каждая запись с разбивкой на страницы, извлекаемая в DynamoDB, сопряжена с прямыми затратами, что делает это негласным правилом при использовании разбивки на страницы в DynamoDB. Эта функция делает нумерацию страниц жизненно важным фактором для ограничения как извлекаемых записей, так и прямых затрат.
Как использовать пагинацию в DynamoDB
1. Пагинация во время операции запроса
В DynamoDB запрос возвращает результаты размером до 1 МБ. Но вы можете эффективно подтвердить, есть ли еще результаты, внимательно изучив свои результаты. Примечательно, что результат низкоуровневой операции запроса содержит элемент LastEvaluatedKey, который не равен NULL, что указывает на наличие дополнительных элементов, связанных с вашим запросом, которые вы должны получить.
Результат без элемента LastEvaluatedKey, который не равен NULL, означает, что все элементы, соответствующие запросу, не превышают лимита в 1 МБ, и элементов для извлечения больше нет. Конечно, вы также можете установить ограничение на количество элементов в результате. См. следующий пример команды:
запрос aws dynamodb \
--table-name MyTableName \
--key-условие-выражение 'PartitionKey = :pk \
--expression-атрибут-значения '{' :пк ':{' С ':' а1234б '}},
--лимит 10 \
Вы можете использовать предыдущую команду, чтобы запросить в таблице элементы с одинаковыми значениями выражения ключевого условия. Давайте найдем в нашей таблице «Заказы» идентификаторы order_Id от Darry Tech. Мы также установили ограничение в 10 элементов на странице. Другой вариант параметра –limit – использовать для той же цели параметр –page-size.
Разбиение на страницы — это автоматическая операция в интерфейсе командной строки AWS для элементов, объем данных которых не превышает 1 МБ. Вы можете добавить к команде эксклюзивный ключ запуска, если хотите, чтобы ваш запрос начинался с определенного порядка.
Ответ выглядит так:
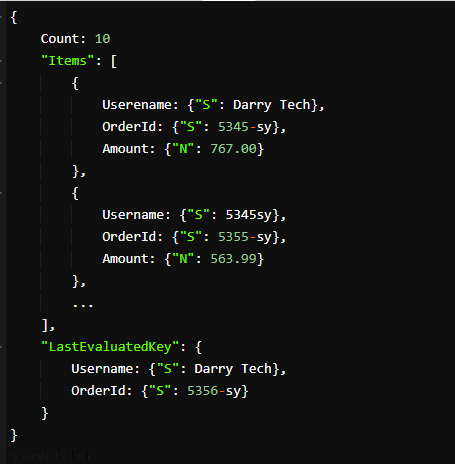
Предоставленные результаты показывают 10 Darry Tech на первой странице. Вы можете использовать значения LastEvaluatedKey, чтобы получить больше заказов, соответствующих значениям ключа выражения вашего поиска, для создания нового запроса. Новый запрос запроса содержит значения LastEvaluatedKey в параметре ExclusiveStartKey.
Пример синтаксиса показан ниже:
запрос aws dynamodb \--table-name Таблица примеров \
--key-условие-выражение 'PartitionKey = :pk \
--expression-атрибут-значения '{' :пк ':{' С ': Дэрри Тек' \
--лимит 10 \
--эксклюзивный-старт-ключ '{' РазделКлюч ':{' С ': Дэрри Тек' }, 'Ключ сортировки' :{ 'С' : '5356' }} '
Предыдущая команда создает следующие заказы на взаимозачет на следующей странице, начиная с идентификатора заказа, имеющего указанный первичный ключ, т. е. {'PartitionKey': {'S': Darry Tech'}', 'SortKey': {'S': «5356-сы»}}.
2. Пагинация во время операций сканирования
Также можно использовать разбиение на страницы для операций сканирования. Все работает так же, как и с командами запросов. Однако вам необходимо использовать атрибут filter-expression. Команда выглядит так, как у нас здесь:
сканирование aws dynamodb \--table-name МояТаблица \
--фильтр-выражение 'ИмяАтрибута = :значение' \
--значения-атрибутов-выражений '{':значение':{'S':'ABC123'}}' \
--лимит двадцать \
--эксклюзивный-старт-ключ '{'PartitionKey':{'S':'ABC123'},'SortKey':{'S':'XYZ987'}}'
Предыдущая команда удаляет до 20 элементов на страницу из таблицы MyTable, начиная с элемента, первичный ключ которого {'PartitionKey': 'ABC123', 'SortKey': 'XYZ987'}. Он фильтрует результаты, чтобы включить только элементы, для которых атрибут AttributeName имеет значение «ABC123».
В ответе ЛастЭвалуатедКей Поле содержит первичный ключ последнего элемента в результирующем наборе. Вы можете использовать это значение в качестве ExclusiveStartKey в последующем сканирование операция для получения следующей страницы результатов.
Заключение
Разбивка на страницы в DynamoDB улучшает управляемость данными. Однако важно знать, выиграют ли ваши системы от разбиения на страницы. Разбиение на страницы необходимо использовать, если у вас длинный список элементов в приложении. Хотя приведенная иллюстрация посвящена вызову AWS CLI, вы также можете использовать разбиение на страницы с помощью AWS SDK, например Python Boto3, или любого другого SDK, который вы предпочитаете.