«Pandas — отличный язык для анализа данных из-за его большой экосистемы пакетов Python, ориентированных на данные. Это упрощает анализ и импорт обоих факторов. Стандартное отклонение — это «типичное» отклонение, полученное из среднего значения. Он часто используется, так как возвращает исходные единицы измерения фрейма данных. Панды использовали std() для вычисления стандартного отклонения. Стандартное отклонение можно рассчитать по заданным значениям, которые могут быть в фрейме данных в виде строки или столбца. Мы будем реализовывать все возможные способы использования стандартного отклонения панд. Для реализации кода мы будем использовать инструмент «spyder», так как он написан в удобной для Python среде».
Синтаксис
«df.std ( ) ”
Следующий синтаксис используется для вычисления стандартного отклонения в фрейме данных. «df» в фрейме данных — это аббревиатура «фрейма данных». Что делает стандартное отклонение? Он измеряет, насколько расширены требуемые данные. Чем больше расширены верхние значения, тем выше должно быть стандартное отклонение.
Возвращаться
Стандартное отклонение pandas возвращает кадр данных, если уровень указан на основе требования.
Обратите внимание, что функция «std ()» автоматически игнорирует значения «NaN» в «df» при расчете стандартного отклонения панд. «NaN» можно объяснить как «не число», что означает, что конкретному значению не присваивается значение.
Ниже приведены методы, которые будут выполняться с примерами стандартного отклонения панд:
-
- Расчет стандартного отклонения Pandas в одном столбце.
- Расчет стандартного отклонения Pandas в нескольких столбцах.
- Расчет стандартного отклонения Pandas для всех числовых столбцов.
- Стандартное отклонение pandas с использованием оси = 1.
- Стандартное отклонение pandas с использованием оси = 0.
Создание кадра данных для расчета стандартного отклонения в Pandas
Сначала откройте программу «spyder». Теперь импортируйте библиотеку pandas как pd. Мы создадим фрейм данных, который состоит из табло с терминами «x», «y» и «z» с очками «22», «10», «11», «16», «12», «45». ', '36' и '40'. У нас есть их значения передач как «8», «9», «13», «7», «22», «24», «4» и «6», а также значение подборов как «17», « 14', '3', 5', '9', '8', '7' и '4'.
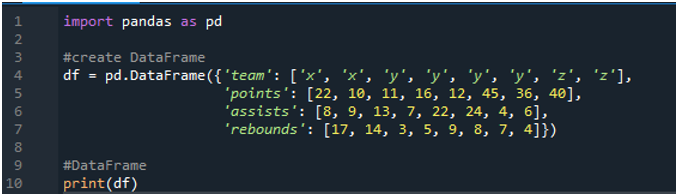
Дисплеи показывают созданный фрейм данных в соответствии со значениями, присвоенными в коде:

Пример # 01: Расчет стандартного отклонения Pandas в одном столбце
В этом примере мы рассчитаем стандартное отклонение одного столбца в кадре данных pandas. Фрейм данных имеет значения команды как «u», «v» и «b» с их точками как «44», «33», «22», «44», «45», «88», «96». ' и '78'. Значения передач равны «7», «8», «9», «10», «11», «14», «18» и «17», а значения подборов равны «11», « 9', '8', '7', '6', '5', '4' и '3'. Столбец «точки» выбирается из фрейма данных для расчета стандартного отклонения одного столбца.
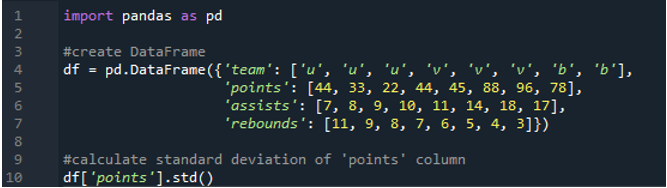
Вывод показывает стандартное отклонение, рассчитанное для столбца «баллы»:

Пример # 02: Расчет стандартного отклонения Pandas в нескольких столбцах
В этом примере мы выполним вычисления стандартного отклонения pandas в нескольких столбцах. В этом кадре данных данные снова представляют собой спортивное табло со значениями команды как «n», «w» и «t» со счетом как «33», «22», «66», «55», «44», «88», «99» и «77». Передачи как «9», «7», «8», «11», «16», «14», «12» и «13» и подборы как «5», «8», «1», « 2», «3», «4», «6» и «7». Здесь мы вычислим стандартное отклонение двух столбцов «точки» и «отскоки», используя функцию std(), примененную к фрейму данных.
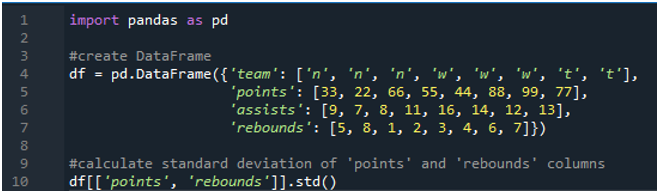
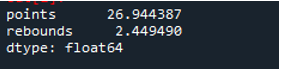
Как мы видим, выходные данные показывают, что стандартное отклонение составило 26,944387 в столбце точек и 2,449490 в столбце отскока соответственно.
Пример # 03: Расчет стандартного отклонения Pandas для всех числовых столбцов
Теперь мы научились вычислять стандартное отклонение одной и нескольких строк. Что, если мы не хотим указывать все имена столбцов в фрейме данных и вычислять весь фрейм данных? Это возможно с помощью простой реализации функции стандартного отклонения pandas для расчета всего фрейма данных в результатах. Фрейм данных здесь состоит из «l», «m» и «o» со значениями очков «33», «36», «79», «78», «58», «55», и две команды набирают одинаковые баллы. то есть '25'. Передачи обозначены как «1», «2», «3», «4», «6», «9», «5» и «7», а их подборы как «14», «10», «2». , «5», «8», «3», «6» и «9». Мы можем рассчитать все стандартные отклонения столбцов с помощью pandas в фрейме данных, используя функцию pandas «std ()».
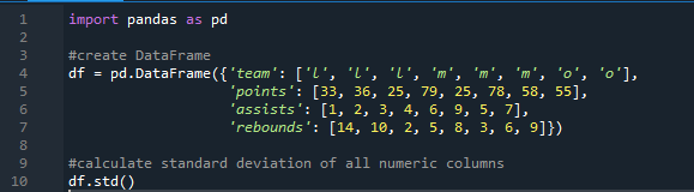
На дисплее отображается рассчитанное стандартное отклонение всего «df», показанное ниже; мы также можем заметить, что панды не рассчитали стандартное отклонение первого столбца, который является «командой», потому что это не числовой столбец.
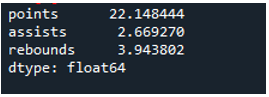
Пример # 04: Стандартное отклонение Pandas с использованием оси = 0
В этом примере в кадрах данных есть команды по видам спорта как «g», «h» и «k» с дополнительными данными. Здесь мы рассчитаем стандартное отклонение, используя ось как «0», параметр, используемый в стандартном отклонении панд. Этот аргумент вычисляет стандартное отклонение по столбцам фрейма данных.
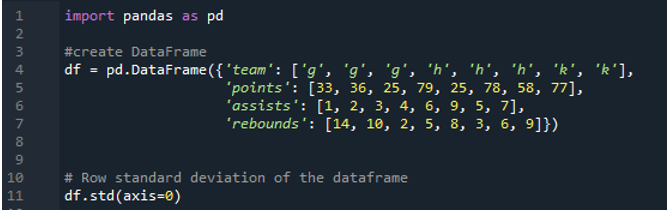
Следующий вывод отображает результаты в столбцах рассчитанного стандартного отклонения. Столбец очков имеет рассчитанное стандартное отклонение как «24,0313062», столбец передач имеет расчетное стандартное отклонение как «2,669270», а расчетное стандартное отклонение столбца отскоков отображается как «3,943802».
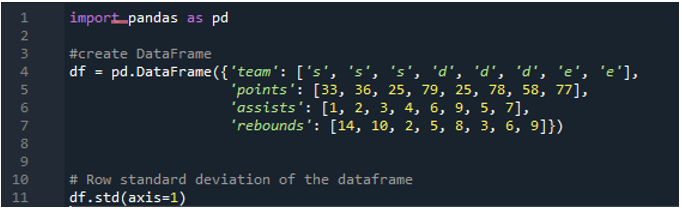
Пример # 05: Стандартное отклонение Pandas с использованием оси = 1
Здесь мы будем использовать параметр оси, которому присвоено значение «1», для вычисления стандартного отклонения в пандах. Какое значение может иметь ось «1»? Аргумент оси «1» вычисляет стандартное отклонение числовых значений в кадре данных по строкам. В кадре данных есть три команды: «s», «d» и «e», с добавлением столбцов данных, созданных как очки команды, передачи команды и подборы команды. Всем направлениям присваиваются разные значения в фрейме данных. Этот параметр оси меняет правила игры, поскольку к тому времени, когда нам нужно будет работать с данными там, где мы хотим, чтобы они были в столбце плюс балл, рассчитанный для выполненного стандартного отклонения.
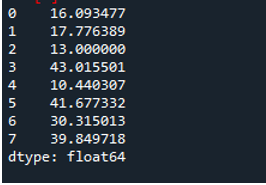
Следующий вывод отображает стандартное отклонение, рассчитанное в строке кадра данных:
Вывод
Стандартное отклонение Pandas — это очень техническая функция, которая является очень полезной функцией, поскольку она находит стандартное отклонение пакта энтузиазма кадров данных pandas. В этой редакционной статье мы изучили методы расчета стандартного отклонения в пандах. Мы выполнили расчеты стандартного отклонения для одного столбца и нескольких столбцов, а также рассчитали стандартное отклонение для всего фрейма данных вместе. Все стратегии работают хорошо, если они используются последовательно и с желаемыми результатами.