Пример 1. Получите позицию шаблона из строки с помощью функции Grep() в R
Чтобы извлечь позицию указанного шаблона из строки, используется функция grep() языка R.
grep('i+', c('fix', 'split', 'кукуруза n', 'краска'), perl=TRUE, value=FALSE)Здесь мы используем функцию grep(), где шаблон «+i» указывается в качестве аргумента, который должен быть сопоставлен с вектором строк. Мы устанавливаем векторы символов, которые содержат четыре строки. После этого мы устанавливаем аргумент «perl» со значением TRUE, которое указывает, что R использует Perl-совместимую библиотеку регулярных выражений, а параметр «value» указывается со значением «FALSE», которое используется для получения индексов элементов. в векторе, соответствующем шаблону.
Позиция шаблона «+i» из каждой строки векторных символов отображается в следующем выводе:

Пример 2. Сопоставление шаблона с помощью функции Greexpr() в R
Затем мы извлекаем позицию индекса вместе с длиной конкретной строки в R с помощью функции gregexpr().
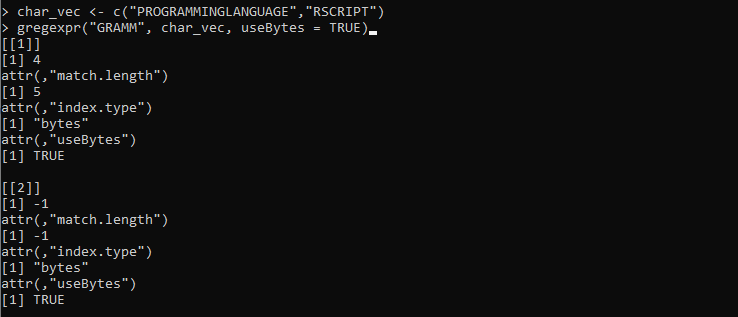
char_vec <- c('ЯЗЫК ПРОГРАММИРОВАНИЯ', 'RSCRIPT')
gregexpr('ГРАММ', char_vec, useBytes = ИСТИНА)
Здесь мы устанавливаем переменную «char_vect», в которой строки содержат разные символы. После этого мы определяем функцию gregexpr(), которая сопоставляет строковый шаблон «GRAMM» со строками, хранящимися в «char_vec». Затем мы устанавливаем параметр useBytes со значением «TRUE». Этот параметр указывает, что сопоставление должно достигаться побайтово, а не посимвольно.
Следующий вывод, полученный из функции gregexpr(), представляет индексы и длину обеих векторных строк:
Пример 3. Подсчет общего количества символов в строке с помощью функции Nchar() в R
Метод nchar(), который мы реализуем ниже, также позволяет нам определить количество символов в строке:
Res <- nchar('Подсчитайте каждый символ')печать (Разрешение)
Здесь мы вызываем метод nchar(), который установлен в переменной «Res». Методу nchar() предоставляется длинная строка символов, которая подсчитывается методом nchar() и определяет количество символов счетчика в указанной строке. Затем мы передаем переменную «Res» методу print(), чтобы увидеть результаты метода nchar().
Результат получен в следующем выводе, который показывает, что указанная строка содержит 20 символов:

Пример 4. Извлечение подстроки из строки с помощью функции Substring() в R
Мы используем метод substring() с аргументами «start» и «stop», чтобы извлечь конкретную подстроку из строки.
str <- substring('УТРО', 2, 4)печать(стр)
Здесь у нас есть переменная «str», в которой вызывается метод substring(). Метод substring() принимает строку «MORNING» в качестве первого аргумента и значение «2» в качестве второго аргумента, который указывает, что второй символ из строки должен быть извлечен, а значение аргумента «4» указывает, что необходимо извлечь четвертый символ. Метод substring() извлекает символы из строки между указанными позициями.
Следующий вывод отображает извлеченную подстроку, которая находится между второй и четвертой позицией в строке:

Пример 5. Объединение строки с помощью функции Paste() в R
Функция Paste() в R также используется для манипуляций со строками, которые объединяют указанные строки путем разделения разделителей.
msg1 <- 'Содержимое'msg2 <- «Запись»
вставить(сообщение1, сообщение2)
Здесь мы указываем строки для переменных «msg1» и «msg2» соответственно. Затем мы используем метод Paste() языка R, чтобы объединить предоставленную строку в одну строку. Метод Paste() принимает переменную strings в качестве аргумента и возвращает одну строку с пробелом по умолчанию между строками.
После выполнения метода Paste() выходные данные представляют собой одну строку с пробелом в ней.

Пример 6. Измените строку с помощью функции Substring() в R
Кроме того, мы также можем обновить строку, добавив подстроку или любой символ в строку с помощью функции substring(), используя следующий скрипт:
str1 <- 'Герои'подстрока(str1, 5, 6) <- 'ic'
cat(' Измененная строка:', str1)
Мы устанавливаем строку «Герои» в переменной «str1». Затем мы развертываем метод substring(), где указывается «str1» вместе со значениями индексов «start» и «stop» подстроки. Методу substring() присваивается подстрока «iz», которая помещается в позицию, указанную в функции для данной строки. После этого мы используем функцию cat() языка R, которая представляет обновленное строковое значение.
Вывод, отображающий строку, обновляется новой с помощью метода substring():

Пример 7. Форматирование строки с помощью функции Format() в R
Однако операция манипулирования строкой в R также включает в себя соответствующее форматирование строки. Для этого мы используем функцию format(), где строку можно выровнять и установить ширину конкретной строки.
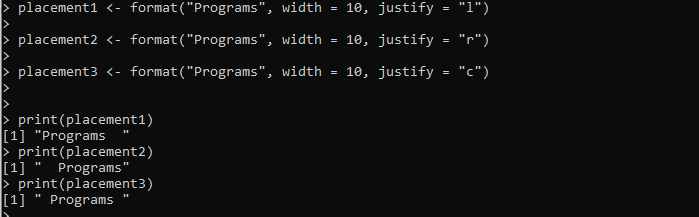
Placement1 <- format('Программы', ширина = 10, justify = 'l')Placement2 <- format('Программы', ширина = 10, justify = 'r')
Placement3 <- format('Программы', ширина = 10, justify = 'c')
печать (размещение1)
печать (размещение2)
печать (размещение3)
Здесь мы устанавливаем переменную «placement1», которая предоставляется методом format(). Мы передаем строку «программы» для форматирования в метод format(). Ширина задается, а выравнивание строки устанавливается по левому краю с помощью аргумента justify. Аналогичным образом мы создаем еще две переменные, «placement2» и «placement2», и применяем метод format() для соответствующего форматирования предоставленной строки.
В выводе отображаются три стиля форматирования для одной и той же строки на следующем изображении, включая выравнивание по левому, правому и центру:
Пример 8. Преобразование строки в нижний и верхний регистр в R
Кроме того, мы также можем преобразовать строку в нижний и верхний регистр, используя функции tolower() и toupper() следующим образом:
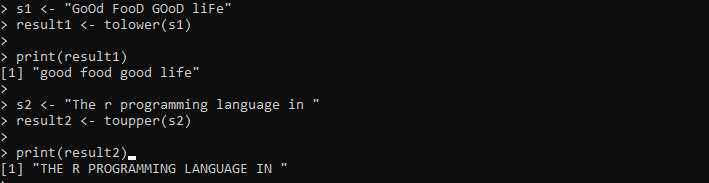
s1 <- «хорошая еда, хорошая жизнь»результат1 <- до нижнего(s1)
печать (результат1)
s2 <- 'Язык программирования r в '
результат2 <- toupper(s2)
печать (результат2)
Здесь мы предоставляем строку, содержащую символы верхнего и нижнего регистра. После этого строка сохраняется в переменной «s1». Затем мы вызываем метод tolower() и передаем в него строку «s1», чтобы преобразовать все символы внутри строки в нижний регистр. Затем мы печатаем результаты метода tolower(), которые хранятся в переменной «result1». Затем мы устанавливаем в переменную «s2» еще одну строку, которая содержит все символы в нижнем регистре. Мы применяем метод toupper() к этой строке «s2», чтобы преобразовать существующую строку в верхний регистр.
В выводе обе строки в указанном случае отображаются на следующем изображении:
Заключение
Мы изучили различные способы управления строками и их анализа, что называется манипулированием строками. Мы извлекли позицию символа из строки, объединили разные строки и преобразовали строку в указанный регистр. Кроме того, мы форматировали строку, изменяли ее и выполняли различные другие операции для управления строкой.