Краткое описание
Этот пост содержит следующие разделы:
- Как использовать агент Async API в LangChain
- Метод 1: использование последовательного выполнения
- Метод 2: использование одновременного выполнения
- Заключение
Как использовать агент Async API в LangChain?
Модели чата одновременно выполняют несколько задач, таких как понимание структуры подсказки, ее сложности, извлечение информации и многое другое. Использование агента Async API в LangChain позволяет пользователю создавать эффективные модели чата, которые могут отвечать на несколько вопросов одновременно. Чтобы изучить процесс использования агента Async API в LangChain, просто следуйте этому руководству:
Шаг 1: Установка фреймворков
Прежде всего, установите фреймворк LangChain, чтобы получить его зависимости от менеджера пакетов Python:
pip установить langchain
После этого установите модуль OpenAI для построения языковой модели, например llm, и настройте ее среду:
pip установить openai
Шаг 2: Среда OpenAI
Следующим шагом после установки модулей является настройка окружения используя ключ API OpenAI и Серпер API для поиска данных от Google:
Импортировать ты
Импортировать получить пропуск
ты . примерно [ 'ОПЕНАЙ_API_KEY' ] '=' получить пропуск . получить пропуск ( «Ключ API OpenAI:» )
ты . примерно [ 'SERPER_API_KEY' ] '=' получить пропуск . получить пропуск ( «Ключ API-интерфейса Serper:» )
Шаг 3. Импорт библиотек
Теперь, когда среда настроена, просто импортируйте необходимые библиотеки, такие как asyncio и другие библиотеки, используя зависимости LangChain:
от лангчейн. агенты Импортировать инициализировать_агент , load_toolsИмпортировать время
Импортировать асинхронный
от лангчейн. агенты Импортировать Тип агента
от лангчейн. llms Импортировать ОпенАИ
от лангчейн. обратные вызовы . стандартный вывод Импортировать StdOutCallbackHandler
от лангчейн. обратные вызовы . трассеры Импортировать LangChainTracer
от айоhttp Импортировать Клиентская сессия
Шаг 4. Вопросы по настройке
Установите набор данных вопросов, содержащий несколько запросов, относящихся к различным доменам или темам, которые можно искать в Интернете (Google):
вопросы '=' [«Кто победитель Открытого чемпионата США в 2021 году» ,
«Сколько лет парню Оливии Уайлд» ,
«Кто является обладателем титула чемпиона мира в Формуле-1» ,
«Кто выиграл женский финал US Open в 2021 году» ,
«Кто муж Бейонсе и сколько ему лет» ,
]
Метод 1: использование последовательного выполнения
После завершения всех шагов просто выполните вопросы, чтобы получить все ответы, используя последовательное выполнение. Это означает, что одновременно будет выполняться/отображаться один вопрос, а также будет возвращено полное время, необходимое для выполнения этих вопросов:
лм '=' ОпенАИ ( температура '=' 0 )инструменты '=' load_tools ( [ 'заголовок Google' , 'ЖМ-математика' ] , лм '=' лм )
агент '=' инициализировать_агент (
инструменты , лм , агент '=' Тип Агента. ZERO_SHOT_REACT_DESCRIPTION , подробный '=' Истинный
)
с '=' время . perf_counter ( )
#настройка счетчика времени, чтобы получить время, затраченное на весь процесс
для д в вопросы:
агент. бегать ( д )
истек '=' время . perf_counter ( ) - с
#распечатываем общее время, затраченное агентом на получение ответов
Распечатать ( ж «Последовательный выпуск выполнен за {elapsed:0.2f} секунд». )
Выход
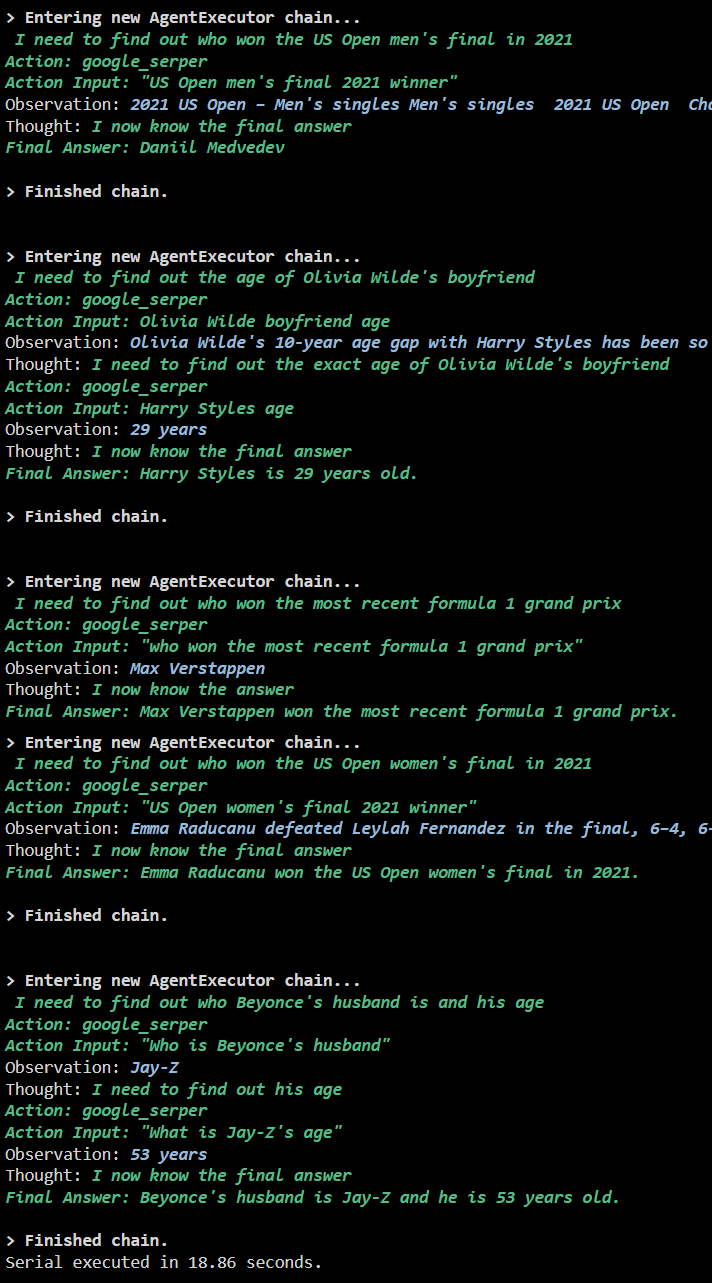
На следующем снимке экрана показано, что на каждый вопрос дается ответ в отдельной цепочке, и как только первая цепочка завершена, вторая цепочка становится активной. Последовательное выполнение требует больше времени, чтобы получить все ответы по отдельности:
Метод 2: использование одновременного выполнения
Метод одновременного выполнения одновременно задает все вопросы и получает на них ответы.
лм '=' ОпенАИ ( температура '=' 0 )инструменты '=' load_tools ( [ 'заголовок Google' , 'ЖМ-математика' ] , лм '=' лм )
#Настройка агента с использованием вышеуказанных инструментов для одновременного получения ответов
агент '=' инициализировать_агент (
инструменты , лм , агент '=' Тип Агента. ZERO_SHOT_REACT_DESCRIPTION , подробный '=' Истинный
)
#настройка счетчика времени, чтобы получить время, затраченное на весь процесс
с '=' время . perf_counter ( )
задания '=' [ агент. болезнь ( д ) для д в вопросы ]
жду асинсио. собирать ( *задания )
истек '=' время . perf_counter ( ) - с
#распечатываем общее время, затраченное агентом на получение ответов
Распечатать ( ж «Одновременное выполнение за {elapsed:0.2f} секунд» )
Выход
Параллельное выполнение извлекает все данные одновременно и занимает гораздо меньше времени, чем последовательное выполнение:
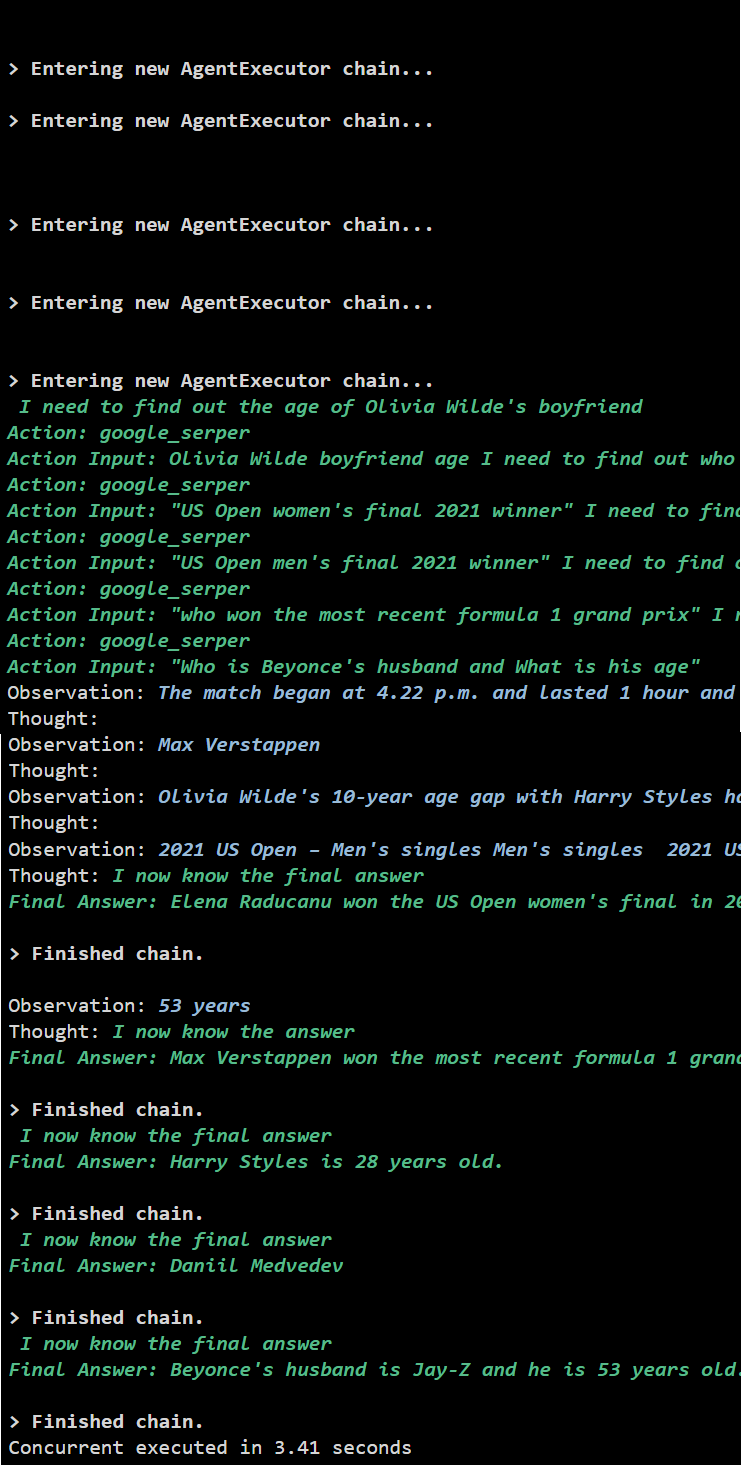
Это все, что касается использования агента Async API в LangChain.
Заключение
Чтобы использовать агент Async API в LangChain, просто установите модули для импорта библиотек из их зависимостей, чтобы получить библиотеку asyncio. После этого настройте среды, используя ключи API OpenAI и Serper, войдя в соответствующие учетные записи. Настройте набор вопросов, связанных с разными темами, и выполняйте цепочки последовательно и одновременно, чтобы получить время их выполнения. В этом руководстве подробно описан процесс использования агента Async API в LangChain.