Это руководство проиллюстрирует процесс использования сводки разговоров в LangChain.
Как использовать сводку разговора в LangChain?
LangChain предоставляет такие библиотеки, как ConversationSummaryMemory, которые могут извлекать полную сводку чата или разговора. Его можно использовать для получения основной информации разговора без необходимости читать все сообщения и текст, доступные в чате.
Чтобы изучить процесс использования сводки разговоров в LangChain, просто выполните следующие шаги:
Шаг 1. Установите модули
Сначала установите инфраструктуру LangChain, чтобы получить ее зависимости или библиотеки, используя следующий код:
pip установить langchain
Теперь установите модули OpenAI после установки LangChain с помощью команды pip:
pip установить openai 
После установки модулей просто настроить среду используя следующий код после получения ключа API от учетной записи OpenAI:
Импортировать тыИмпортировать получить пропуск
ты . примерно [ 'ОПЕНАЙ_API_KEY' ] '=' получить пропуск . получить пропуск ( «Ключ API OpenAI:» )
Шаг 2. Использование сводки разговора
Приступите к использованию сводки разговора, импортировав библиотеки из LangChain:
от лангчейн. Память Импортировать РазговорСводкаПамять , ЧатСообщениеИсторияот лангчейн. llms Импортировать ОпенАИ
Настройте память модели с помощью методов ConversationSummaryMemory() и OpenAI() и сохраните в ней данные:
Память '=' РазговорСводкаПамять ( лм '=' ОпенАИ ( температура '=' 0 ) )Память. save_context ( { 'вход' : 'привет' } , { 'выход' : 'привет' } )
Запустите память, вызвав load_memory_variables() метод извлечения данных из памяти:
Память. load_memory_variables ( { } ) 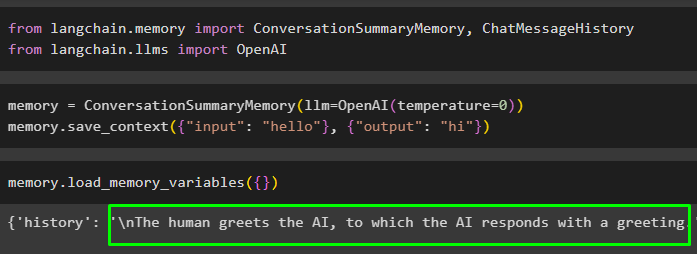
Пользователь также может получить данные в форме разговора, например, каждый объект с отдельным сообщением:
Память '=' РазговорСводкаПамять ( лм '=' ОпенАИ ( температура '=' 0 ) , return_messages '=' Истинный )Память. save_context ( { 'вход' : 'привет' } , { 'выход' : 'Привет как дела' } )
Чтобы получить сообщение ИИ и людей отдельно, выполните метод load_memory_variables():
Память. load_memory_variables ( { } ) 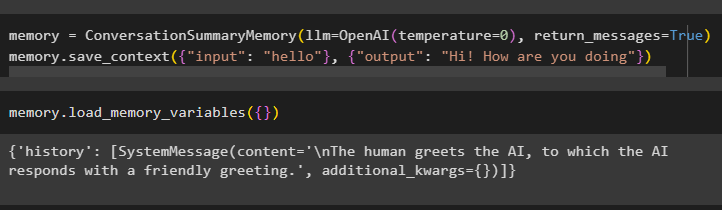
Сохраните сводку разговора в памяти, а затем выполните команду памяти, чтобы отобразить сводку разговора/разговора на экране:
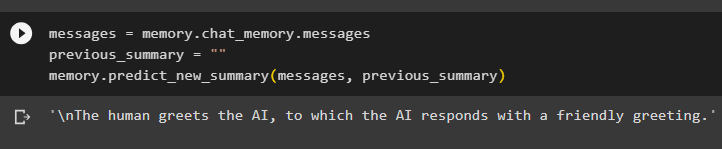
Сообщения '=' Память. чат_память . Сообщенияprevious_summary '=' ''
Память. предсказать_new_summary ( Сообщения , previous_summary )
Шаг 3. Использование сводки разговора с существующими сообщениями
Пользователь также может получить сводку разговора, который существует за пределами класса или чата, используя сообщение ChatMessageHistory(). Эти сообщения можно добавить в память, чтобы автоматически генерировать сводку всего разговора:
история '=' ЧатСообщениеИстория ( )история. add_user_message ( 'привет' )
история. add_ai_message ( 'всем привет!' )
Создайте модель, такую как LLM, используя метод OpenAI() для выполнения существующих сообщений в чат_память переменная:
Память '=' РазговорСводкаПамять. from_messages (лм '=' ОпенАИ ( температура '=' 0 ) ,
чат_память '=' история ,
return_messages '=' Истинный
)
Выполните память, используя буфер, чтобы получить сводку существующих сообщений:
Память. буфер 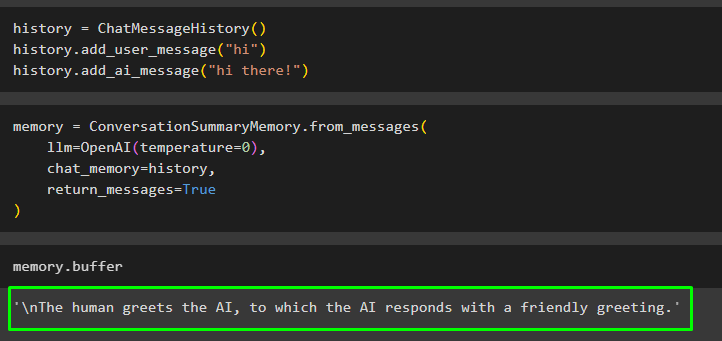
Выполните следующий код, чтобы создать LLM, настроив буферную память с помощью сообщений чата:
Память '=' РазговорСводкаПамять (лм '=' ОпенАИ ( температура '=' 0 ) ,
буфер '=' '''Человек спрашивает машину о себе
Система отвечает, что ИИ создан во благо, поскольку он может помочь людям реализовать свой потенциал''' ,
чат_память '=' история ,
return_messages '=' Истинный
)
Шаг 4. Использование сводки разговора в цепочке
Следующий шаг объясняет процесс использования сводки разговора в цепочке с использованием LLM:
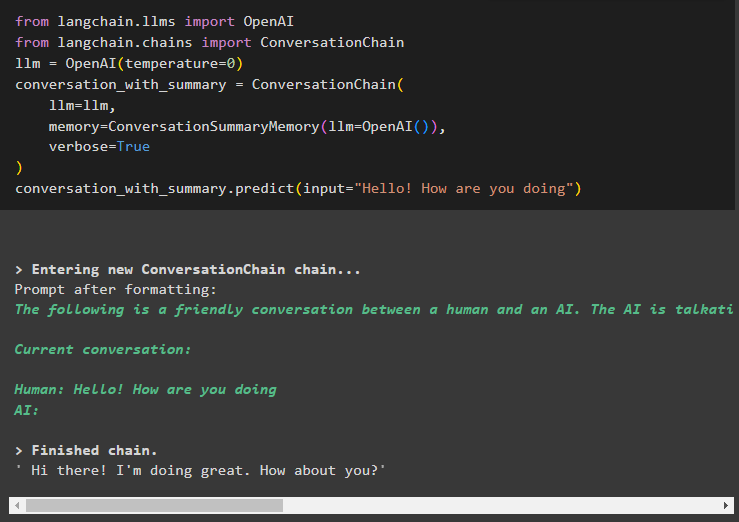
от лангчейн. llms Импортировать ОпенАИот лангчейн. цепи Импортировать Разговорная цепочка
лм '=' ОпенАИ ( температура '=' 0 )
разговор_with_summary '=' Разговорная цепочка (
лм '=' лм ,
Память '=' РазговорСводкаПамять ( лм '=' ОпенАИ ( ) ) ,
подробный '=' Истинный
)
разговор_с_сводкой. предсказывать ( вход '=' 'Привет, как поживаешь' )
Здесь мы начали выстраивать цепочки, начав разговор с вежливого вопроса:
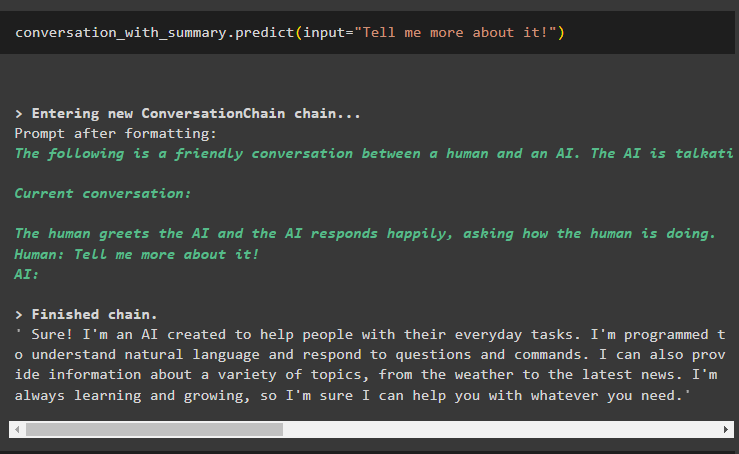
Теперь вступайте в разговор, спросив немного больше о последнем выводе, чтобы расширить его:
разговор_с_сводкой. предсказывать ( вход '=' 'Расскажи мне больше об этом!' )Модель объяснила последнее сообщение подробным описанием технологии искусственного интеллекта или чат-бота:
Извлеките интересную информацию из предыдущего вывода, чтобы направить разговор в определенном направлении:
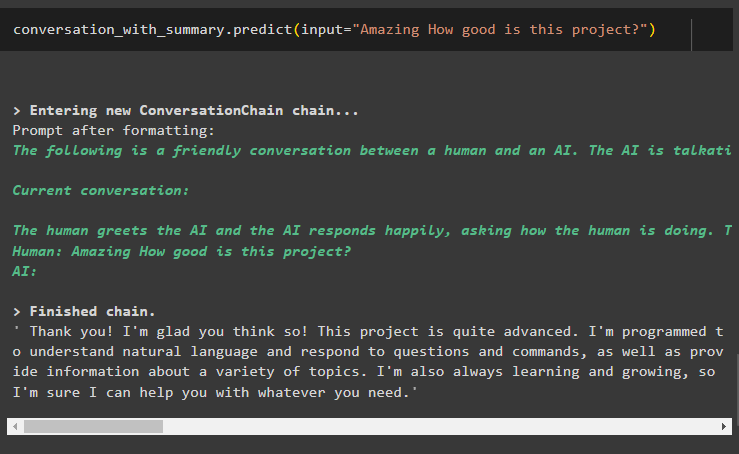
разговор_с_сводкой. предсказывать ( вход '=' «Удивительно, насколько хорош этот проект?» )Здесь мы получаем подробные ответы от бота, используя библиотеку памяти сводки разговоров:
Это все, что касается использования сводки разговоров в LangChain.
Заключение
Чтобы использовать сводное сообщение разговора в LangChain, просто установите модули и платформы, необходимые для настройки среды. После настройки среды импортируйте РазговорСводкаПамять библиотека для создания LLM с использованием метода OpenAI(). После этого просто используйте сводку разговора, чтобы извлечь подробные выходные данные из моделей, которые представляют собой сводку предыдущего разговора. В этом руководстве подробно описан процесс использования сводной памяти разговоров с помощью модуля LangChain.