«В «пандах» мы можем легко прочитать текстовый файл с помощью метода «панд». «Панды» предоставляют нам возможность прочитать текстовый файл. «Панды» предоставляют различные встроенные методы для чтения текстового файла. Мы обсудим все методы в этом уроке вместе со всеми параметрами здесь и объясним их подробно. Кроме того, мы будем читать текстовый файл в «пандах», используя методы «панд» в наших кодах здесь».
Методы чтения текстового файла в «пандах»
В «пандах» у нас есть три метода, которые помогают нам читать текстовый файл. Мы также сделали здесь несколько примеров, в которых мы читаем текстовый файл. Методы, которые предоставляет «панда», обсуждаются ниже:
-
- Используя метод pd.read_csv().
- Используя метод pd.read_table().
- Используя метод pd.read_fwf().
Теперь мы объясним синтаксис всех этих методов, а также подробно обсудим параметры всех методов в этом руководстве.
Синтаксис read_csv()
pd.read_csv ( «имя файла.txt», сен знак равно заголовок = Нет, имена знак равно [ «Имя_столбца1», «Имя_столбца2, «Имя_столбца2», ………….. ] )
В этом методе мы сначала добавляем имя текстового файла, данные которого мы хотим прочитать, и это первый параметр этого метода. Затем мы помещаем «sep», который является разделителем в этом методе, и мы помещаем пробел здесь как символ, чтобы он считал пробел разделителем. После этого у нас есть параметр заголовка, и используется значение «Нет» этого параметра, поэтому он создаст заголовок по умолчанию, и если мы не добавим этот параметр, то он будет рассматривать первую строку текстового файла. как заголовок. В параметре «имена» мы можем добавить имена столбцов, которые мы должны добавить в качестве заголовка.
Синтаксис read_table()
pd.read_table ( 'имя файла.txt' , разделитель = ' ' )
В этом методе мы помещаем имя файла текстового файла в качестве первого параметра. В разделителе, когда мы помещаем ‘ ’, он будет использовать символ пробела в качестве разделителя.
Синтаксис read_fwf()
pd.read_fwf ( 'имя файла.txt' )
Этот метод принимает только один параметр — имя текстового файла.
Теперь мы будем использовать эти методы для чтения текстовых файлов в кодах «панд» и отображения данных текстового файла на терминале.
Пример #01
Здесь находится приложение «Spyder», в котором мы сделали все эти коды, представленные в этом руководстве. Текстовый файл, данные которого мы хотим прочитать, показан ниже. Мы будем использовать метод «read_csv()» для чтения этого текстового файла в «пандах».
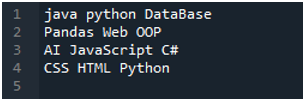
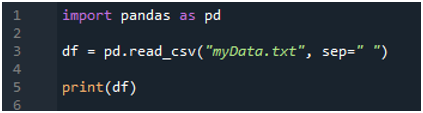
Сначала мы импортируем библиотеку «pandas», потому что мы хотим использовать метод «read_csv ()», а это метод «pandas». Мы обращаемся к этому методу только тогда, когда мы импортировали библиотеку «панд». Здесь мы упоминаем «панды как pd», поэтому этот «pd» помещается вместе с названием метода его использования. После этого мы создаем здесь переменную «df», которая используется для хранения данных текстового файла после чтения. Мы размещаем здесь метод «pd.read_csv()», который помогает читать текстовый файл и преобразовывать данные текстового файла в DataFrame и сохранять их в переменной «df».
Здесь мы передали имя файла «myData.txt», а затем использовали «sep» и присвоили этому «sep» пустой символ. Итак, этот пробел работает как разделитель в текстовом файле. Затем мы использовали «print ()» ниже, который используется для печати данных текстового файла. Он будет отображать данные текстового файла в форме DataFrame.
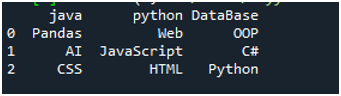
Для выполнения этого кода мы должны нажать «Shift + Enter», и вывод будет отображаться на терминале «Spyder». Результат приведенного выше кода отображается на данном снимке экрана, и вы можете видеть, что данные текстового файла отображаются как DataFrame, а первая строка нашего текстового файла представлена здесь как имена столбцов этого DataFrame. Он также разделяет данные, в которых в текстовом файле присутствует символ пробела.
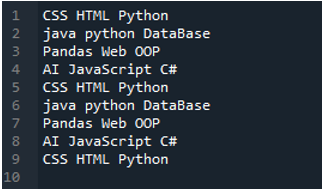
Пример #02
Здесь показан текстовый файл, который мы будем читать в этом примере, и мы снова воспользуемся методом «read_csv()», но с другими параметрами.
Используется метод «pandas» «pd.read_csv()», и мы передаем здесь три параметра. Сначала мы размещаем имя файла «Record.txt». Второй параметр — это параметр «sep», который присваивает ему пустой символ, а затем у нас есть третий параметр, в котором мы устанавливаем «заголовок» и настраиваем его на «Нет», поэтому он создаст заголовок по умолчанию для DataFrame. когда мы выполняем этот код. Все это мы сохранили в переменной «My_Record», а также добавили «My_Record» в функцию «print()» для печати.

Все данные сохраняются в DataFrame, и он разделяет данные, в которых присутствует символ пробела в данных текстового файла. Кроме того, здесь был создан заголовок DataFrame по умолчанию, потому что мы установили для параметра «header» значение «None».
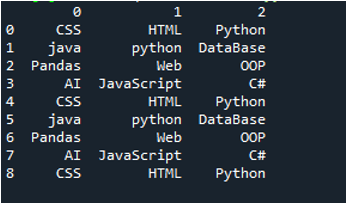
Пример #03
Отобразится текстовый файл этого примера, и мы еще раз воспользуемся методом «read_csv()» с измененными параметрами.
В этом коде четыре параметра передаются здесь методу «pandas» «pd.read_csv()». Имя текстового файла является первым параметром. Параметру «sep» присваивается пробел во втором параметре. Для параметра «заголовок» установлено значение «Нет» в третьем аргументе, а в качестве четвертого параметра мы установили «имена», которые будут отображаться в качестве имен столбцов DataFrame после чтения текстового файла, и эти имена столбцов «COL_1, COL_2, COL_3, COL_4 и COL_5». Вся эта информация была сохранена в переменной «My_Record», а «My_Record» также была добавлена к методу «print ()», поэтому она будет распечатываться на терминале.

Вся информация текстового файла отображается здесь как DataFrame, а также разделяет данные, в которые в текстовом файле добавляются пробелы. Он также соответственно добавляет имена столбцов, которые мы добавили выше в коде.
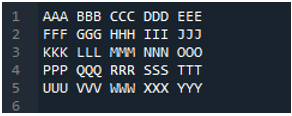
Пример #04
Это текстовый файл, который мы будем читать в этом примере, используя другой метод, метод «pd.read_table()».
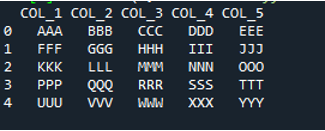
Здесь добавлен метод «pd.read_table ()» для чтения текстового файла, и мы добавляем «ABC.txt», который является именем текстового файла. Этот метод помогает читать текстовый файл, а также мы настроили параметр «разделитель» на символ пробела, поэтому он также будет работать как разделитель, который мы объяснили выше. Затем все данные текстового файла сохраняются в переменной «My_Data» и также распечатываются здесь.

Начальная строка нашего текстового файла показана здесь как имена столбцов DataFrame, а данные текстового файла печатаются как DataFrame. Кроме того, он разделяет данные текстового файла, в котором присутствует символ пробела.
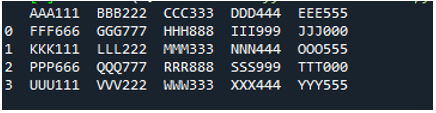
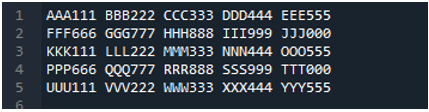
Пример #05
Теперь текстовый файл содержит данные, которые отображаются ниже. На этот раз мы применим «read_fwf()» и покажем, как он отображает данные после чтения текстового файла.
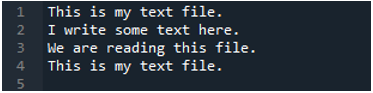
Как мы знаем, этот метод «read_fwf()» принимает только один параметр — имя файла, который мы хотим прочитать. Мы добавляем сюда «textfile.txt», которое является именем нашего текстового файла, и назначаем этот метод pandas переменной «File_Data», которая будет хранить данные этого текстового файла. Затем мы помещаем «print (File_Data)», чтобы он также распечатывал эти данные.

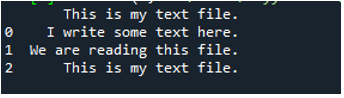
Здесь показаны все данные текстового файла. Она не разделяла данные, в которых присутствуют пробелы, потому что в этой функции нет таких параметров, как «Sep» или «разделитель».
Вывод
В этом руководстве объясняется, как читать текстовый файл в «пандах» и какие методы используются для чтения текстового файла в «пандах». Мы обсудили все методы, которые помогают нам читать текстовый файл в «пандах». В этом руководстве мы рассмотрели три различных метода «панд» для чтения наших текстовых файлов в «пандах». Мы также подробно объяснили синтаксис всех методов, а также параметры всех методов здесь и прочитали множество текстовых файлов, применяя различные методы со всеми возможными параметрами в этом руководстве.