Это руководство проиллюстрирует процесс загрузки цепочек из LangChain Hub.
Как добавить состояние памяти в цепочку с помощью LangChain?
Состояние памяти можно использовать для инициализации цепочек, поскольку оно может ссылаться на последнее значение, хранящееся в цепочках, которое будет использоваться при возврате вывода. Чтобы изучить процесс добавления состояния памяти в цепочки с использованием платформы LangChain, просто прочтите это простое руководство:
Шаг 1. Установите модули
Во-первых, приступите к процессу, установив фреймворк LangChain с его зависимостями с помощью команды pip:
pip установить langchain
Установите также модуль OpenAI, чтобы получить его библиотеки, которые можно использовать для добавления состояния памяти в цепочку:
pip установить openai
Получите ключ API от учетной записи OpenAI и настроить среду используя его, чтобы цепи могли получить к нему доступ:
Импортировать ты
Импортировать получить пропуск
ты . примерно [ 'ОПЕНАЙ_API_KEY' ] '=' получить пропуск . получить пропуск ( «Ключ API OpenAI:» )
Этот шаг важен для правильной работы кода.
Шаг 2. Импортируйте библиотеки
После настройки среды просто импортируйте библиотеки для добавления состояния памяти, такие как LLMChain, ConversationBufferMemory и многие другие:
от лангчейн. цепи Импортировать Разговорная цепочкаот лангчейн. Память Импортировать РазговорБуферПамять
от лангчейн. чат_модели Импортировать ЧатOpenAI
от лангчейн. цепи . лм Импортировать ЛМЧейн
от лангчейн. подсказки Импортировать Шаблон приглашения
Шаг 3: Построение цепочек
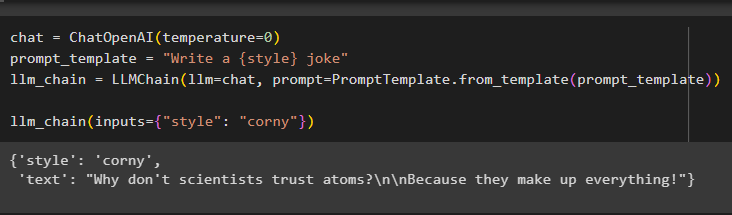
Теперь просто постройте цепочки для LLM, используя метод OpenAI() и шаблон приглашения, используя запрос для вызова цепочки:
чат '=' ЧатOpenAI ( температура '=' 0 )подсказка_шаблон '=' «Напиши шутку {style}»
llm_chain '=' ЛМЧейн ( лм '=' чат , быстрый '=' Шаблон запроса. from_template ( подсказка_шаблон ) )
llm_chain ( входы '=' { 'стиль' : 'банальный' } )
Модель отобразила выходные данные с использованием модели LLM, как показано на снимке экрана ниже:
Шаг 4: Добавление состояния памяти
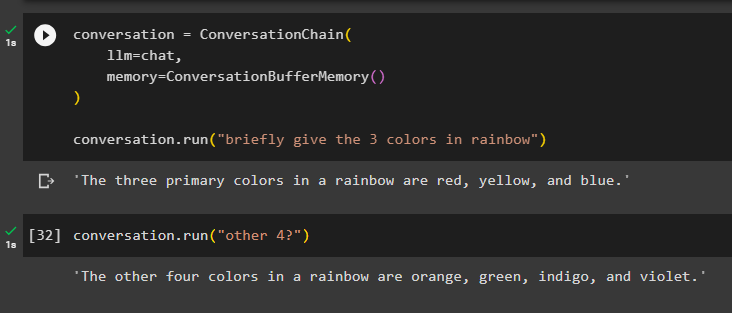
Здесь мы собираемся добавить состояние памяти в цепочку с помощью метода ConversationBufferMemory() и запустить цепочку, чтобы получить 3 цвета радуги:
беседа '=' Разговорная цепочка (лм '=' чат ,
Память '=' РазговорБуферПамять ( )
)
беседа. бегать ( «Коротко назови 3 цвета радуги» )
Модель отображает только три цвета радуги, а контекст хранится в памяти цепочки:
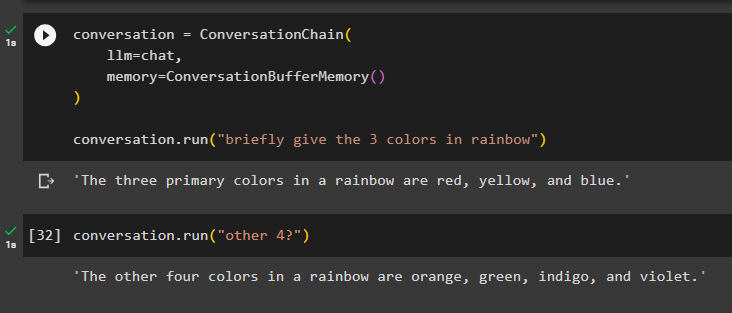
Здесь мы запускаем цепочку неоднозначной командой типа « еще 4? », поэтому модель сама получает контекст из памяти и отображает оставшиеся цвета радуги:
беседа. бегать ( 'остальные 4?' )Модель сделала именно это, поскольку поняла контекст и вернула оставшиеся четыре цвета из набора радуги:
Вот и все, что касается загрузки цепочек из LangChain Hub.
Заключение
Чтобы добавить память цепочками с помощью фреймворка LangChain, просто установите модули, чтобы настроить среду для построения LLM. После этого импортируйте библиотеки, необходимые для построения цепочек в LLM, а затем добавьте в него состояние памяти. После добавления состояния памяти в цепочку просто дайте цепочке команду, чтобы получить выходные данные, а затем дайте другую команду в контексте предыдущей, чтобы получить правильный ответ. В этом посте подробно описан процесс добавления состояния памяти в цепочки с использованием платформы LangChain.