В этом руководстве будет показано, как использовать VectorStoreRetrieverMemory с использованием платформы LangChain.
Как использовать VectorStoreRetrieverMemory в LangChain?
VectorStoreRetrieverMemory — это библиотека LangChain, которую можно использовать для извлечения информации/данных из памяти с использованием векторных хранилищ. Хранилища векторов можно использовать для хранения данных и управления ими для эффективного извлечения информации в соответствии с подсказкой или запросом.
Чтобы изучить процесс использования VectorStoreRetrieverMemory в LangChain, просто прочтите следующее руководство:
Шаг 1. Установите модули
Запустите процесс использования средства извлечения памяти, установив LangChain с помощью команды pip:
pip установить langchain
Установите модули FAISS для получения данных с помощью поиска по семантическому сходству:
pip установить faiss-gpu 
Установите модуль chromadb для использования базы данных Chroma. Он работает как векторное хранилище для создания памяти для ретривера:
pip установить хромадб 
Для установки необходим еще один модуль tiktoken, который можно использовать для создания токенов путем преобразования данных в более мелкие фрагменты:
pip установить тиктокен 
Установите модуль OpenAI, чтобы использовать его библиотеки для создания LLM или чат-ботов с использованием его среды:
pip установить openai 
Настройте среду в Python IDE или блокноте, используя ключ API из учетной записи OpenAI:
Импортировать тыИмпортировать получить пропуск
ты . примерно [ 'ОПЕНАЙ_API_KEY' ] '=' получить пропуск . получить пропуск ( «Ключ API OpenAI:» )
Шаг 2. Импортируйте библиотеки
Следующий шаг — получить библиотеки из этих модулей для использования ретривера памяти в LangChain:
от лангчейн. подсказки Импортировать Шаблон приглашенияот дата и время Импортировать дата и время
от лангчейн. llms Импортировать ОпенАИ
от лангчейн. вложения . опенай Импортировать OpenAIEmbeddings
от лангчейн. цепи Импортировать Разговорная цепочка
от лангчейн. Память Импортировать ВекторМагазинРетриверПамять
Шаг 3. Инициализация хранилища векторов
В этом руководстве используется база данных Chroma после импорта библиотеки FAISS для извлечения данных с помощью команды ввода:
Импортировать Фейссот лангчейн. врачебный магазин Импортировать InMemoryДокторский магазин
#импорт библиотек для настройки баз данных или векторных хранилищ
от лангчейн. вектормагазины Импортировать ФАИСС
#создавайте вложения и тексты для хранения их в векторных хранилищах
embedding_size '=' 1536
индекс '=' файс. Индексная квартираL2 ( embedding_size )
встраивание_fn '=' OpenAIEmbeddings ( ) . embed_query
векторный магазин '=' ФАИСС ( встраивание_fn , индекс , InMemoryДокторский магазин ( { } ) , { } )
Шаг 4. Создание Retriever, поддерживаемого векторным хранилищем
Создайте память для хранения самых последних сообщений в беседе и получения контекста чата:
ретривер '=' векторный магазин. as_retriever ( search_kwargs '=' диктовать ( к '=' 1 ) )Память '=' ВекторМагазинРетриверПамять ( ретривер '=' ретривер )
Память. save_context ( { 'вход' : 'Я люблю есть пиццу' } , { 'выход' : 'фантастика' } )
Память. save_context ( { 'вход' : «Я хорошо играю в футбол» } , { 'выход' : 'хорошо' } )
Память. save_context ( { 'вход' : «Я не люблю политику» } , { 'выход' : 'конечно' } )
Проверьте память модели, используя введенные пользователем данные с ее историей:
Распечатать ( Память. load_memory_variables ( { 'быстрый' : «Какой вид спорта мне посмотреть?» } ) [ 'история' ] ) 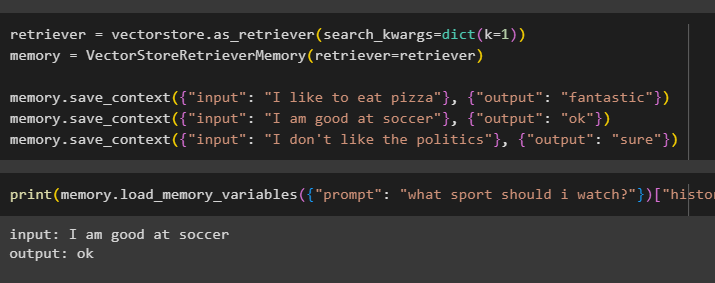
Шаг 5: Использование Retriever в цепочке
Следующий шаг — использование ретривера памяти с цепочками путем построения LLM с помощью метода OpenAI() и настройки шаблона подсказки:
лм '=' ОпенАИ ( температура '=' 0 )_DEFAULT_TEMPLATE '=' '''Это взаимодействие человека и машины.
Система выдает полезную информацию с подробностями, используя контекст.
Если у системы нет для вас ответа, она просто говорит: «У меня нет ответа».
Важная информация из разговора:
{история}
(если текст неактуален, не используйте его)
Текущий чат:
Человек: {вход}
ИИ: '''
БЫСТРЫЙ '=' Шаблон приглашения (
входные_переменные '=' [ 'история' , 'вход' ] , шаблон '=' _DEFAULT_TEMPLATE
)
#настройте ConversationChain(), используя значения его параметров
разговор_with_summary '=' Разговорная цепочка (
лм '=' лм ,
быстрый '=' БЫСТРЫЙ ,
Память '=' Память ,
подробный '=' Истинный
)
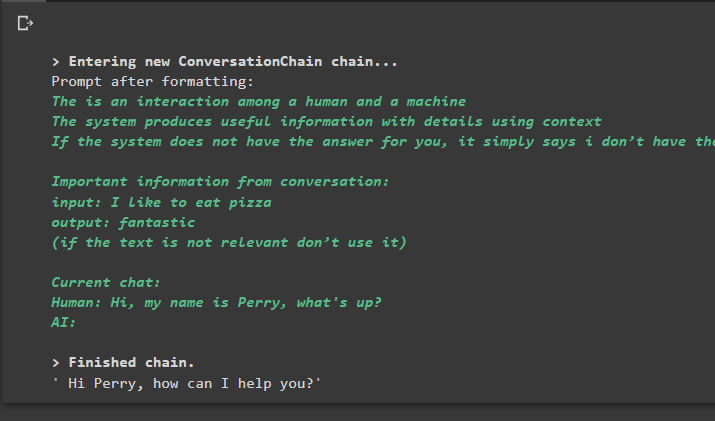
разговор_с_сводкой. предсказывать ( вход '=' «Привет, меня зовут Перри, как дела?» )
Выход
Выполнение команды запускает цепочку и отображает ответ, предоставленный моделью или LLM:
Продолжайте разговор, используя подсказку на основе данных, хранящихся в векторном хранилище:
разговор_с_сводкой. предсказывать ( вход '=' «какой мой любимый вид спорта?» ) 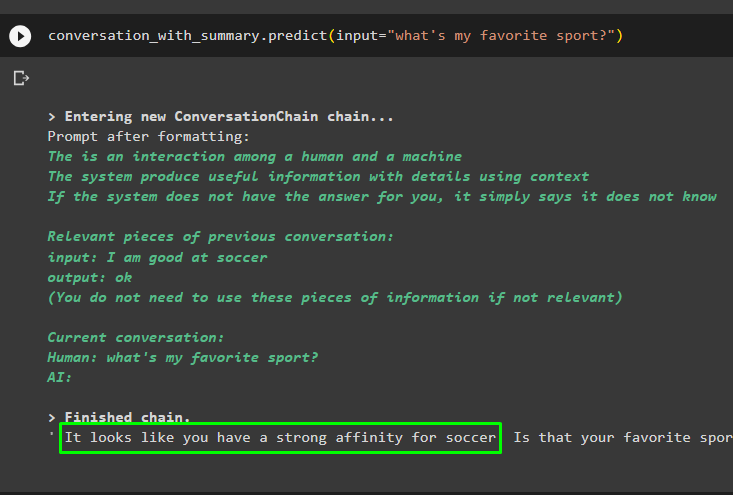
Предыдущие сообщения хранятся в памяти модели, которую модель может использовать для понимания контекста сообщения:
разговор_с_сводкой. предсказывать ( вход '=' «Какая моя любимая еда» ) 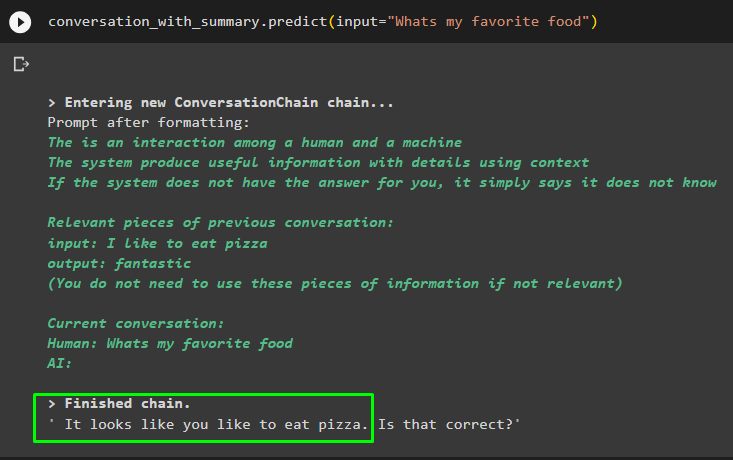
Получите ответ, предоставленный модели в одном из предыдущих сообщений, чтобы проверить, как средство извлечения памяти работает с моделью чата:
разговор_с_сводкой. предсказывать ( вход '=' 'Как меня зовут?' )Модель правильно отобразила выходные данные, используя поиск по сходству из данных, хранящихся в памяти:
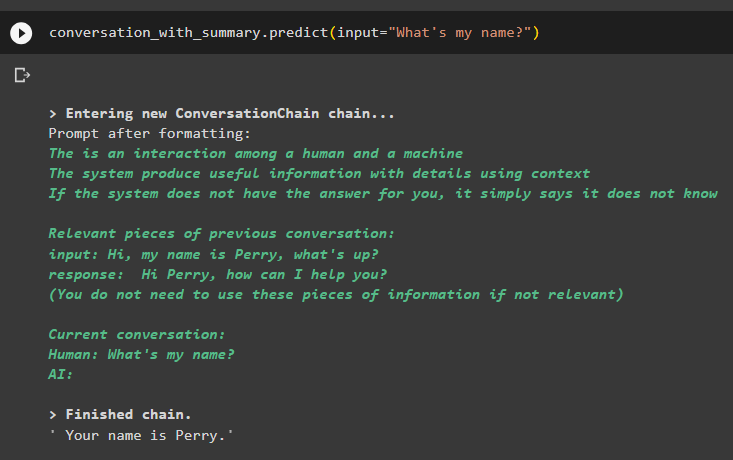
Вот и все, что касается использования средства извлечения векторного хранилища в LangChain.
Заключение
Чтобы использовать ретривер памяти на основе векторного хранилища в LangChain, просто установите модули и фреймворки и настройте среду. После этого импортируйте библиотеки из модулей для построения базы данных с помощью Chroma, а затем установите шаблон приглашения. Протестируйте ретривер после сохранения данных в памяти, начав разговор и задав вопросы, связанные с предыдущими сообщениями. В этом руководстве подробно описан процесс использования библиотеки VectorStoreRetrieverMemory в LangChain.