Оптимизация кода Python с помощью инструментов профилирования
Настроив Google Colab для оптимизации кода Python с помощью инструментов профилирования, мы начнем с настройки среды Google Colab. Если мы новичок в Colab, то это важная и мощная облачная платформа, которая обеспечивает доступ к блокнотам Jupyter и ряду библиотек Python. Мы получаем доступ к Colab, посетив (https://colab.research.google.com/) и создав новый блокнот Python.
Импортируйте библиотеки профилирования
Наша оптимизация основана на умелом использовании библиотек профилирования. Двумя важными библиотеками в этом контексте являются cProfile и line_profiler.
Импортировать cПрофиль
Импортировать линия_профилер
Библиотека «cProfile» — это встроенный инструмент Python для профилирования кода, а «line_profiler» — внешний пакет, который позволяет нам идти еще глубже, анализируя код построчно.
На этом этапе мы создаем образец скрипта Python для вычисления последовательности Фибоначчи с использованием рекурсивной функции. Давайте проанализируем этот процесс более подробно. Последовательность Фибоначчи представляет собой набор чисел, в котором каждое последующее число представляет собой сумму двух предыдущих. Обычно он начинается с 0 и 1, поэтому последовательность выглядит как 0, 1, 1, 2, 3, 5, 8, 13, 21 и так далее. Это математическая последовательность, которая обычно используется в качестве примера в программировании из-за ее рекурсивной природы.
Мы определяем функцию Python под названием «Фибоначчи» в рекурсивной функции Фибоначчи. Эта функция принимает в качестве аргумента целое число «n», представляющее позицию в последовательности Фибоначчи, которую мы хотим вычислить. Мы хотим найти пятое число в последовательности Фибоначчи, например, если «n» равно 5.
защита Фибоначчи ( н ) :
Далее мы устанавливаем базовый вариант. Базовый вариант рекурсии — это сценарий, который завершает вызовы и возвращает заранее определенное значение. В последовательности Фибоначчи, когда «n» равно 0 или 1, мы уже знаем результат. 0-е и 1-е числа Фибоначчи равны 0 и 1 соответственно.
если н <= 1 :возвращаться н
Этот оператор «if» определяет, меньше ли «n» или равно 1. Если да, мы возвращаем само «n», поскольку дальнейшая рекурсия не требуется.
Рекурсивный расчет
Если «n» превышает 1, продолжаем рекурсивный расчет. В данном случае нам необходимо найти «n»-е число Фибоначчи, суммируя «(n-1)»-е и «(n-2)»-е числа Фибоначчи. Мы достигаем этого, делая два рекурсивных вызова внутри функции.
еще :возвращаться Фибоначчи ( н - 1 ) + Фибоначчи ( н - 2 )
Здесь «фибоначчи(n – 1)» вычисляет «(n-1)»-е число Фибоначчи, а «fibonacci(n – 2)» вычисляет «(n-2)»-е число Фибоначчи. Мы добавляем эти два значения, чтобы получить желаемое число Фибоначчи в позиции «n».
Таким образом, эта функция «фибоначчи» рекурсивно вычисляет числа Фибоначчи, разбивая проблему на более мелкие подзадачи. Он выполняет рекурсивные вызовы, пока не достигнет базового случая (0 или 1), возвращая известные значения. Для любого другого «n» он вычисляет число Фибоначчи путем суммирования результатов двух рекурсивных вызовов «(n-1)» и «(n-2)».
Хотя эта реализация проста для вычисления чисел Фибоначчи, она не самая эффективная. На последующих этапах мы будем использовать инструменты профилирования, чтобы выявить и оптимизировать ограничения производительности для сокращения времени выполнения.
Профилирование кода с помощью CProfile
Теперь мы профилируем нашу функцию «фибоначчи», используя «cProfile». Это упражнение по профилированию дает представление о времени, затрачиваемом на каждый вызов функции.
cпрофилер '=' cПрофиль. Профиль ( )cprofiler. давать возможность ( )
результат '=' Фибоначчи ( 30 )
cprofiler. запрещать ( )
cprofiler. print_stats ( Сортировать '=' 'кумулятивный' )
В этом сегменте мы инициализируем объект «cProfile», активируем профилирование, запрашиваем функцию «fibonacci» с «n=30», деактивируем профилирование и отображаем статистику, отсортированную по совокупному времени. Это первоначальное профилирование дает нам общее представление о том, какие функции потребляют больше всего времени.
! pip install line_profilerИмпортировать cПрофиль
Импортировать линия_профилер
защита Фибоначчи ( н ) :
если н <= 1 :
возвращаться н
еще :
возвращаться Фибоначчи ( н - 1 ) + Фибоначчи ( н - 2 )
cпрофилер '=' cПрофиль. Профиль ( )
cprofiler. давать возможность ( )
результат '=' Фибоначчи ( 30 )
cprofiler. запрещать ( )
cprofiler. print_stats ( Сортировать '=' 'кумулятивный' )
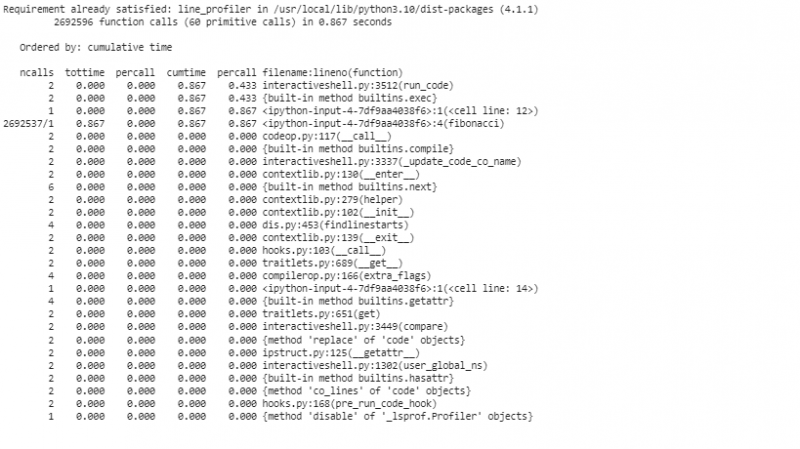
Чтобы профилировать код построчно с помощью line_profiler для более детального анализа, мы используем «line_profiler» для сегментации нашего кода построчно. Прежде чем использовать «line_profiler», мы должны установить пакет в репозиторий Colab.
! pip install line_profilerТеперь, когда у нас есть готовый «line_profiler», мы можем применить его к нашей функции «fibonacci»:
%load_ext line_profilerзащита Фибоначчи ( н ) :
если н <= 1 :
возвращаться н
еще :
возвращаться Фибоначчи ( н - 1 ) + Фибоначчи ( н - 2 )
%lprun -f фибоначчи фибоначчи ( 30 )
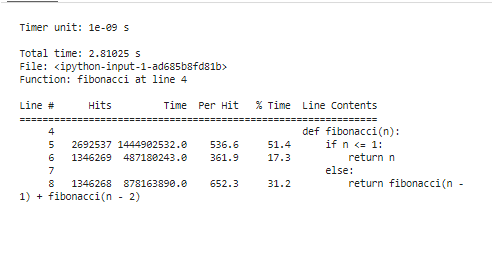
Этот фрагмент начинается с загрузки расширения «line_profiler», определяет нашу функцию «fibonacci» и, наконец, использует «%lprun» для профилирования функции «fibonacci» с «n=30». Он предлагает построчную сегментацию времени выполнения, точно определяя, где наш код расходует свои ресурсы.
После запуска инструментов профилирования для анализа результатов ему будет представлен массив статистики, показывающий характеристики производительности нашего кода. Эта статистика включает общее время, затраченное на каждую функцию, и продолжительность каждой строки кода. Например, мы можем заметить, что функция Фибоначчи тратит немного больше времени на пересчет одних и тех же значений несколько раз. Это избыточные вычисления, и это явная область, где можно применить оптимизацию либо посредством мемоизации, либо с помощью итеративных алгоритмов.
Теперь мы проводим оптимизацию там, где мы определили потенциальную оптимизацию нашей функции Фибоначчи. Мы заметили, что функция несколько раз пересчитывает одни и те же числа Фибоначчи, что приводит к ненужной избыточности и замедлению времени выполнения.
Чтобы оптимизировать это, мы реализуем мемоизацию. Мемоизация — это метод оптимизации, который предполагает сохранение ранее рассчитанных результатов (в данном случае чисел Фибоначчи) и их повторное использование при необходимости вместо их пересчета. Это уменьшает количество избыточных вычислений и повышает производительность, особенно для рекурсивных функций, таких как последовательность Фибоначчи.
Чтобы реализовать мемоизацию в нашей функции Фибоначчи, мы напишем следующий код:
# Словарь для хранения вычисленных чисел Фибоначчифиб_кэш '=' { }
защита Фибоначчи ( н ) :
если н <= 1 :
возвращаться н
# Проверяем, кэширован ли уже результат
если н в фиб_кэш:
возвращаться фиб_кэш [ н ]
еще :
# Вычисляем и кэшируем результат
фиб_кэш [ н ] '=' Фибоначчи ( н - 1 ) + Фибоначчи ( н - 2 )
возвращаться фиб_кэш [ н ] ,
В этой модифицированной версии функции «fibonacci» мы вводим словарь «fib_cache» для хранения ранее вычисленных чисел Фибоначчи. Прежде чем вычислить число Фибоначчи, мы проверяем, есть ли оно уже в кеше. Если да, мы возвращаем кэшированный результат. В любом другом случае мы вычисляем его, сохраняем в кеше и затем возвращаем.
Повторение профилирования и оптимизации
После реализации оптимизации (в нашем случае мемоизации) очень важно повторить процесс профилирования, чтобы узнать влияние наших изменений и убедиться, что мы улучшили производительность кода.
Профилирование после оптимизации
Мы можем использовать те же инструменты профилирования, «cProfile» и «line_profiler», для профилирования оптимизированной функции Фибоначчи. Сравнивая новые результаты профилирования с предыдущими, мы можем измерить эффективность нашей оптимизации.
Вот как мы можем профилировать оптимизированную функцию «фибоначчи» с помощью «cProfile»:
cпрофилер '=' cПрофиль. Профиль ( )cprofiler. давать возможность ( )
результат '=' Фибоначчи ( 30 )
cprofiler. запрещать ( )
cprofiler. print_stats ( Сортировать '=' 'кумулятивный' )
Используя «line_profiler», мы профилируем его построчно:
%lprun -f фибоначчи фибоначчи ( 30 )Код:
# Словарь для хранения вычисленных чисел Фибоначчифиб_кэш '=' { }
защита Фибоначчи ( н ) :
если н <= 1 :
возвращаться н
# Проверяем, кэширован ли уже результат
если н в фиб_кэш:
возвращаться фиб_кэш [ н ]
еще :
# Вычисляем и кэшируем результат
фиб_кэш [ н ] '=' Фибоначчи ( н - 1 ) + Фибоначчи ( н - 2 )
возвращаться фиб_кэш [ н ]
cпрофилер '=' cПрофиль. Профиль ( )
cprofiler. давать возможность ( )
результат '=' Фибоначчи ( 30 )
cprofiler. запрещать ( )
cprofiler. print_stats ( Сортировать '=' 'кумулятивный' )
%lprun -f фибоначчи фибоначчи ( 30 )
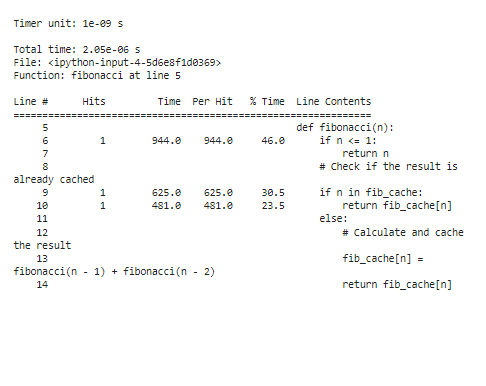
Для анализа результатов профилирования после оптимизации время выполнения будет значительно сокращено, особенно для больших значений «n». Благодаря мемоизации мы видим, что функция теперь тратит гораздо меньше времени на пересчет чисел Фибоначчи.
Эти шаги необходимы в процессе оптимизации. Оптимизация включает в себя внесение осознанных изменений в наш код на основе наблюдений, полученных в результате профилирования, а повторение профилирования гарантирует, что наши оптимизации приведут к ожидаемому повышению производительности. Путем итеративного профилирования, оптимизации и проверки мы можем точно настроить наш код Python, чтобы обеспечить более высокую производительность и улучшить взаимодействие с пользователем наших приложений.
Заключение
В этой статье мы обсудили пример, в котором мы оптимизировали код Python с помощью инструментов профилирования в среде Google Colab. Мы инициализировали пример вместе с настройкой, импортировали необходимые библиотеки профилирования, написали образцы кода, профилировали его с помощью «cProfile» и «line_profiler», рассчитали результаты, применили оптимизации и итеративно улучшили производительность кода.